【Big Data 每日一题20180814】hadoop中有几个文件,spark就会有几个Partition么?
本文共 849 字,大约阅读时间需要 2 分钟。
spark中的几个概念File,Block,Split,Task,Partition,RDD以及节点数、Executor数、core数目的关系
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数、Executor数、core数目的关系。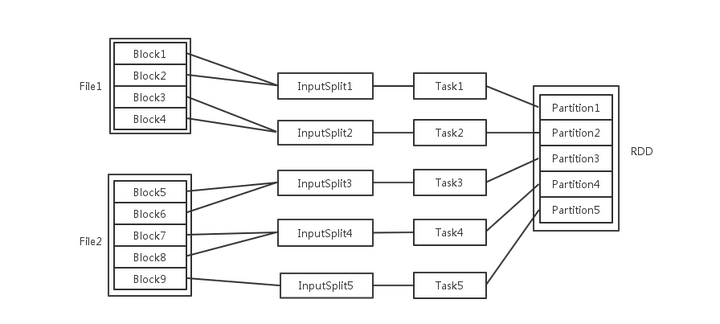
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
链接:https://www.zhihu.com/question/33270495/answer/93424104
来源:知乎转载地址:http://kyvmi.baihongyu.com/
你可能感兴趣的文章
定时器的使用
查看>>
为Android加入busybox工具
查看>>
使用技巧busybox
查看>>
如何查看与/dev/input目录下的event对应的设备
查看>>
bootloader-bootable解析
查看>>
bootloader (LK)&&android lk bootloader中相关修改指南
查看>>
SD卡驱动分析--基于高通平台
查看>>
SD Card 驱动流程分析
查看>>
Linux之debugfs介绍
查看>>
关于sd卡中一些概念的理解
查看>>
sd卡驱动分析之相关硬件操作和总结
查看>>
linux dd命令解析
查看>>
S3C2440上touchscreen触摸屏驱动
查看>>
USB History Viewing
查看>>
怎样做可靠的分布式锁,Redlock 真的可行么?
查看>>
[图文] Seata AT 模式分布式事务源码分析
查看>>
pm 源码分析
查看>>
Sending the User to Another App
查看>>
kmsg_dump
查看>>
Getting a Result from an Activity
查看>>